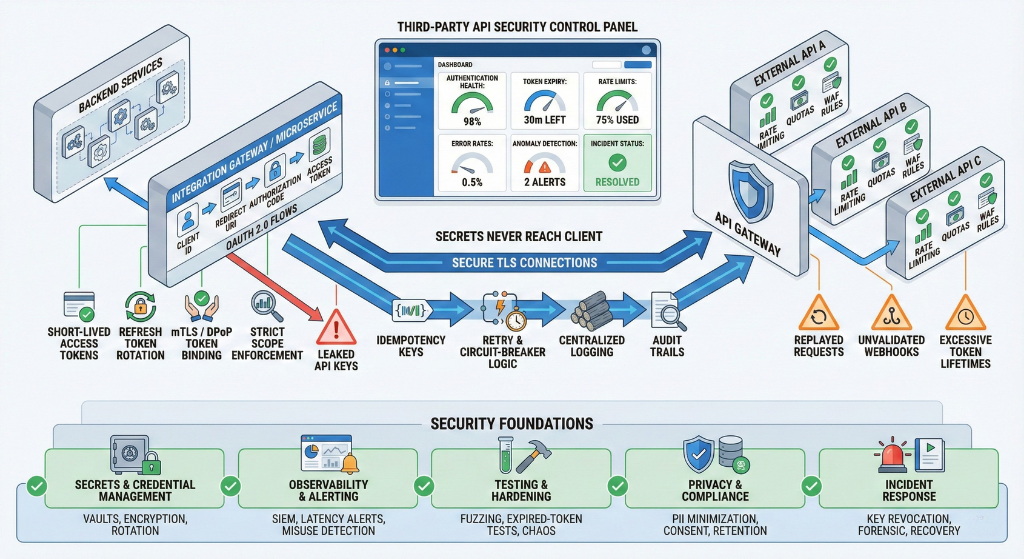
A comprehensive, operational checklist covering architecture, auth, secrets, protection, observability, testing, privacy, and incident response. Use this before design, during implementation, and as part of ongoing audits.
1. High-level design & architecture
Objective clarity (must document): user-scoped delegated access (user acts), server-to-server service access (machine acts), or delegated access with user consent. Select design based on data ownership and revocation needs.
Decisions & checks
- Document integration objective and required data flows (one-page design brief).
- Prefer OAuth 2.0 / delegated auth where the provider supports it — avoids storing user secrets and enables user revocation. If OAuth is not used, document justification.
- Execute third-party calls server-side by default (keeps secrets secret, centralizes policy, enables logging/throttling). Client-side only if provider explicitly supports short-lived public flows (e.g., OAuth implicit/PKCE patterns).
- For server-side, centralize calls behind either:
- a stateless proxy with request transformation and auth enforcement; or
- a dedicated integration microservice per vendor (better isolation, quotas).
- For multi-tenant apps enforce tenant isolation: per-tenant credentials, scoped permissions, per-tenant rate limits and separate logs/metrics.
Deliverable: Integration design doc + diagram (flow, token flows, isolation boundaries).
2. Authentication, authorization & token strategy
Auth model selection
- Inventory provider auth options (API keys, OAuth2, OIDC, mutual TLS, JWT). Choose highest-security option compatible with use case. Prefer OAuth2 (authorization code + PKCE for public clients; client_credentials for server-to-server).
- Use short-lived access tokens; implement refresh token rotation and, where available, sender-constrained tokens (DPoP / mTLS).
Scope & least privilege
- Request minimal scopes first; expand only when necessary. Document scope rationale per flow.
- Enforce least privilege at both request time and stored credentials.
Proof-of-possession
- Use mTLS or DPoP if provider supports it to bind tokens to a client and prevent reuse if leaked.
Deliverable: Auth policy table mapping flow → grant type → token lifetime → scope.
3. Secrets & credential handling (storage, use, rotation)
Storage & encryption
- Store secrets only in purpose-built secret stores (AWS Secrets Manager, Azure Key Vault, Google Secret Manager, HashiCorp Vault). Do not store in source, config files, or container images.
- Secrets must be encrypted at rest; KMS keys separated from DB access and restricted to minimal principals.
Rotation & lifecycle
- Automate credential rotation (frequency based on sensitivity — e.g., every 30–90 days for high-risk keys). Document rotation flows and ensure services can re-read rotated secrets without downtime.
- Prefer short-lived ephemeral credentials (IAM role tokens) where possible.
CI/CD & pipelines
- Put secrets in pipeline secret storage (not environment variables captured in logs). Ensure build logs strip secrets and secret scanning runs on PRs.
Deliverable: Secret management policy + rotation automation playbook.
4. Client-side considerations (web & mobile)
No embedded secrets
- Never embed long-lived secrets in client bundles or mobile binaries. If client needs to call third-party directly, use OAuth with PKCE and short lifetimes.
Secure storage
- For web SPAs: store tokens in httpOnly, Secure cookies or in memory; avoid localStorage for refresh tokens.
- For mobile: use platform secure stores (Keychain, Keystore) and consider certificate pinning for critical flows.
Token minimization
- Limit token scope and lifetime for client flows. Implement refresh using server or secure gateway where possible.
Replay/abuse prevention
- Assume network traffic is observable; design so copied network requests cannot be reused successfully (short-lived tokens, origin checks, additional server validation).
Deliverable: Client security guideline + token storage rules.
5. Server-side integration & request flow
Centralized enforcement
- Route third-party calls through a central integration layer to enforce auth, rate limits, retries, and audit logging.
Idempotency
- Implement idempotency keys for non-idempotent operations (payments, writes) to avoid duplicate side effects from retries.
TLS & certificate validation
- Enforce TLS for every external call; validate certificates and use up-to-date CA bundles. Monitor cert expiry.
Resilience
- Implement circuit breakers, backoff/retry strategies, queueing for async operations, and graceful degradation (fallback UX) for unavailable third parties.
Deliverable: Integration runbook with idempotency and retry policies.
6. API protection, usage controls & abuse prevention
Gateway & policy
- Place an API gateway (or service mesh + gateway) in front of integration endpoints to centralize auth, WAF rules, quotas, and analytics.
Rate limiting & quotas
- Enforce strict per-API-key, per-tenant, and per-endpoint limits. Distinguish read vs write limits and allow burst vs steady tokens.
Anomaly detection
- Configure automated anomaly detection (spikes, geo anomalies, unusual user agents) with automated mitigation actions (throttle/block + alert).
Consumption tiers
- For public partner APIs, enforce consumption tiers to limit impact of copied requests.
Deliverable: Gateway policy configuration + quota tables.
7. Observability, logging & alerting
Audit-grade logging
- Log request id, timestamp, tenant/user id, endpoint, response code, latency, and non-sensitive parameters. Never log full tokens or card-like strings.
Monitoring & SIEM
- Forward logs/metrics to monitoring platforms (Datadog, CloudWatch, ELK, SIEM) with alerts for error rates, latency, auth failures, and unusual patterns.
Token misuse detection
- Detect same token used from multiple IPs or rapid geographic hops; alert and optionally revoke.
Deliverable: Observability playbook + alert thresholds.
8. Testing, QA & hardening
Failure mode testing
- Test expired tokens, invalid scopes, 429 rate limits, timeouts, partial responses, and webhook retries in sandbox.
Security testing
- Include API-level pen tests, replay attack simulations, fuzzing, and dependency/third-party security reviews.
Secret scanning
- Integrate secret scanning in CI to fail PRs with accidental secrets. Run periodic audits for leaked tokens.
Load testing
- Perform load and chaos testing to examine rate-limit behavior and backoff correctness.
Deliverable: QA test matrix and security test schedule.
9. Privacy, compliance & vendor risk
PII & consent
- Map PII flows created by third-party data and ensure lawful basis and user consent where required (GDPR/CCPA).
Vendor risk
- Obtain DPAs, assess vendor security posture (SOC2, ISO27001, PCI as required), and ensure breach notification clauses in contracts.
Retention & deletion
- Define retention policies for third-party tokens/data and implement deletion/erase workflows on user request.
Deliverable: Compliance checklist and vendor risk assessment.
10. Revoke, rotation & incident response
Revocation
- Ability to revoke keys/tokens per user/tenant quickly (admin console + API). Document propagation windows.
Compromise recovery
- Incident playbook: rotate affected keys, re-encrypt stored tokens, notify impacted tenants, run forensics, and issue postmortem with CAPA.
Automation
- Automate revocation and rotation procedures; test runbooks periodically.
Deliverable: Incident response playbook and revocation automation scripts.
11. Practical anti-abuse controls for “network tab copy/paste”
Structural protections
- Do not rely on obscurity. Prevent replay of captured requests by:
- short token life, refresh rotation, token binding;
- origin verification and server-side validation of client identity;
- requiring additional per-action nonces or re-auth for state changes;
- per-key quotas and usage tiers that limit damage.
Behavioral controls
- Detect replay via timestamp validation, reuse detection, and anomalous geo/IP patterns; automatically revoke suspicious tokens.
Deliverable: Replay prevention checklist and mitigation rules.
12. Developer ergonomics & operational controls
Developer experience
- Provide a partner developer portal with sandbox keys, sample code, rate limits, and best practices to avoid misuse.
Error messaging
- Provide helpful developer errors without leaking internal topology or secrets.
Automation
- Document and automate rotation schedules and environment promotion flows.
Deliverable: Developer portal spec + automation playbook.
13. Quick red-flag checklist (fast audit)
- Any secret in source code or public repo → FAIL.
- Long-lived credentials in mobile/web bundle → FAIL.
- No rate limiting / quotas → HIGH RISK.
- No logging/monitoring of third-party calls → OPERATIONAL RISK.
- No plan for rotation/revocation → POLICY GAP.
- Webhooks not validated or origin unchecked → SECURITY RISK.
- Tokens usable from any IP with no binding → ABUSE RISK.
Final operational recommendations
- Prefer OAuth / delegated auth whenever possible. Document exceptions.
- Centralize third-party calls server-side behind an integration layer or microservice.
- Use secret managers and automated rotation — no manual or ad-hoc key handling.
- Enforce rate limits and per-tenant quotas at the gateway.
- Log, monitor, and alert on auth failures and abnormal usage; automate token revocation.
- Test for real failure modes and rehearse incident response.